PHONETIC POSTERIORGRAMS FOR MANY-TO-ONE VOICE CONVERSION WITHOUT PARALLEL DATA TRAINING
基于音素后验图不使用平行数据训练的多到一的声音转换
http://www1.se.cuhk.edu.hk/~lfsun/ICME2016_Lifa_Sun.pdf
0. 摘要
这篇文章提出了一种新颖的使用非平行训练数据的声音转换方法。这个想法通过使用由SI-ASR获得的PPGs的均值联系不同的说话者。方法假设PPGs可以代表说话者标准化空间中的语音发音,并且独立于说话者对应的语音内容。提议的方法首先获取目标说话者(target speech)的PPGs。随后使用基于深双向长短期记忆的递归神经网络(DBLSTM)对目标说话者的PPGs与声学特征之间的关系进行建模。为了转换任意的源语音,我们从相同的SI-ARS中获得PPGs,并将其输入一个已训练的DBLSTM中生成转换的语音。我们的方法有两个主要的优点:1)不需要平行的训练数据;2)一个训练模型可以应用在任意源说话者上转换为固定的目标说话者。实验表明,我们的方法与目前最好的系统相比在语音质量和与说话者的相似度上有相当或者更胜的表现。
00. 图片
PPGs
Baseline
Proposal

1. 概述
半机翻
语音转换(Voice conversion,VC)旨在修改一个说话人的语音,使其听起来像是由另一个特定的说话人说的。VC可广泛应用于计算机辅助语音修剪系统的个性化反馈、语音障碍对象的个性化语音辅助工具开发、不同人声的电影配音等领域。
经典的VC的工作方法如下:首先将说相同内容的语音片段(e.g. frames)对齐。而后,建立source 声学特征与 target 声学特征的映射。以前的许多VC研究都依赖于并行训练数据,在并行训练数据中,源说话人和目标说话人同时说出相同的句子来进行语音记录。Stylianou et al. [1] 提出一种基于高斯混合模型(GMMs)的连续概率变换方法。Toda et al. [2]通过使用全局方差来减轻过度平滑效果,提高了基于GMM的方法的性能。Wu et al. [3] 提出了一种基于非负矩阵分解的语音样本直接合成转换语音的方法。Nakashika et al. [4] 采用深度神经网络(DNN)对高阶空间中的源和目标进行映射。Sun et al. [5] 提出了一种基于深度双向长短期记忆的递归神经网络(DBLSTM)方法,利用语音的频谱特征和上下文信息(context information)来建立源语音和目标语音之间的关系模型。
平行数据训练的VC的发展简述
上面提到的方法都有较好的效果。但是,在实际中平行数据是不容易得到的。因此,一些研究者提出了一些使用非平行数据的VC方法,这是一个更加有挑战的问题。大部分方法都着眼于寻找合适的帧对齐(frame alignments)这并不是直接明了的。Erro et al. [6] 提出了一种迭代对齐方法,对非平行话语中的语音等效声矢量进行配对。Tao et al. [7] 提出了一种以语音信息为约束的监控数据对齐方法。Siĺen et al. [8] 将动态核偏最小二乘回归方法与迭代对准算法相结合,对非并行数据进行了扩展。Benisty et al. [9] 利用时间上下文信息提高非并行数据的迭代对齐精度。
不幸的是,实验结果[6-9]表明,非并行数据的VC性能不如并行数据的VC。这种结果是合理的,因为很难使非平行对准和平行对准一样精确。Aryal et al. [10] 提出了一种完全不同的方法,利用electromagnetic articulography(EMA)估计的发音行为(articulatory behavior)。基于不同的说话人在说相同的语音内容时具有相同的发音行为(如果他们的发音区域是标准化的)的信念,作者将标准化的EMA特征作为源说话人和目标说话人之间的桥梁。在将目标说话者的EMA features特征映射到声学特征进行建模之后,声音转换可以通过驱动一个使用源说话者EMA特征训练的模型来实现。
[10] proposed a very different approach that made use of articulatory behavior estimated by electromagnetic articulography (EMA). With the belief that different speakers have the same articulatory behavior (if their articulatory areas are normalized) when they speak the same spoken content, the authors took normalized EMA features as a bridge between the source and target speakers. After modeling the mapping between EMA features and acoustic features of the target speaker, VC can beachieved by driving the trained model with EMA features of the source speaker.
我们的方法受到[10]的启发。但是我们使用更加容易得到的PPGs作为说话者之间的桥梁,替代掉需要非常昂贵获得的EMA特征。PPG是一个时间与类别(time-versus-class)的矩阵,表示一个语句中每一个特定时间帧对应每一个音素类别的概率[11, 12]。1]我们提出的方法应用一个独立于说话者的自动语音识别系统(SI-ASR)来生成PPGs用来均衡说话者的差异。2]然后,我们使用DBLSTM结构对得到的PPGs和对应的目标说话者的声学特征进行建模,为了生成语音参数。3]最后我们通过使用源说话者的PPGs(来自相同的SI-ASR模型)来驱动训练好的DBLSTM模型进行声音转换。 注意我们没有使用除来自SI-ASR的PPGs之外的其他语音内容信息。我们提出的方法有以下几个优点:1. 不需要平行训练数据 2. 不需要对齐,可以避免可能的对齐错误产生的影响 3. 训练的模型可以被用在别的源说话者,只有目标说话者是固定的(即多对一的转换)。但在最好的平行数据训练方法中,一个训练模型只能被用在特定的源说话者上(即一对一的转换)。
本文的其余部分安排如下:第2节介绍了一个最优的依赖于并行训练数据的VC系统,将该系统作为我们的baseline。 第3节介绍了我们提出的使用PPG的VC方法。 第4节介绍了实验和我们建议的方法与baseline的比较,包括客观和主观方面。 第五部分总结了本文。
2. 基线系统
基于DBLSTM 使用平行训练数据VC
2.1 DBLSTM的基本框架
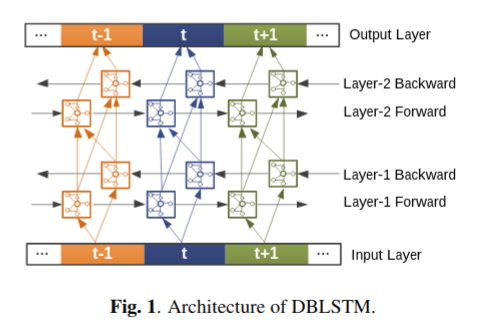
如Fig.1. 所示,DBLSTM是一个序列到序列的映射模型。中间的部分和左右两边的部分(被分别记为t, t-1, t+1) 分别表示当前帧,前一帧和后一帧。图1中每一个正方形代表一个记忆块,包含自连接(self-connection)的存储单元(memory cell)和三个门单元(即输入、输出和忘记门forget gates),它们分别提供写入、读取和复位操作。此外,每一层的双向连接可以在前向和后向两个方向上充分利用上下文信息。
DBLSTM网络结构包含记忆块和循环连接,这使得它可以储存更长时间段的信息,并且学习最佳数量的上下文信息[5] [13]。
2.2 训练阶段和转换阶段
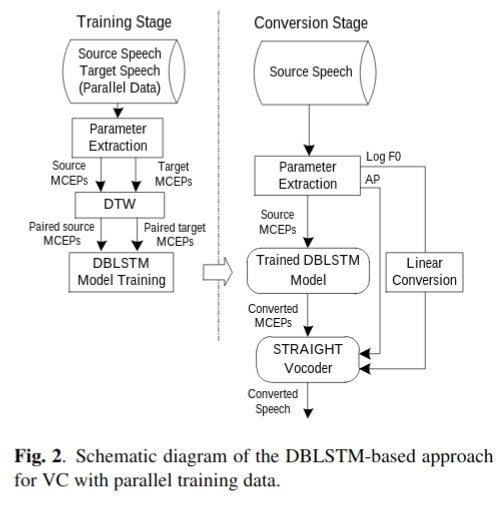
基线方法被划分为训练阶段和转换阶段,如Fig. 2. 描述。
在训练阶段,使用STAIGHT[14]抽取谱包络(spectral envelope)。抽取Mel-cepstral coefficients(MCEPs)特征用来表示谱包络,之后将来自源语音和目标语音的MCEPs用动态时间规整(DTW)对齐。然后,将源语音和目标语音的MCEPs配对作为训练数据。通过时间反向传播(BPTT)来训练DBLSTM模型。
在转换过程中,首先从一个源语句中抽取基频(fundamental frequwncy, F0),MCEPs 和 非周期成分(aperiodic component, AP) 。然后,转换语音的参数用如下方式生成:使用训练的DBLSTM模型映射MCEPs。均衡源语和目标语的均值和标准差来转换 \(log F0\) 。直接复制AP。最后,使用STRAIGHT vocoder来合成语音波形。
2.3 限制
尽管基于DBLSTM的方法具有良好的性能,但它有以下局限性:1)依赖于代价昂贵的并行训练数据;2)DTW(dynamic time warping)误差对VC输出质量的影响是不可避免的。
对齐的误差
3. 提议系统
使用PPGs的非平行数据VC
为了解决基线方法的一些限制,我们提出了一种基于PPGs的方法,来自SI-ASR系统的PPGs是可以连接不同说话者的(can bridge across speakers)。
3.1 概观
如Fig.3描述,提议系统被分为三个阶段:训练阶段1, 训练阶段2, 转换阶段。SI-ASR模型用于获取输入语音的PPGs表示。训练阶段2对目标说话者PPGs与MCEPs之间的关系进行建模用于语音参数的生成。转化阶段使用来自源说话者的PPGs(来自相同的SI-ASR系统)来驱动训练好的DBLSTM模型进行声音转换。PPGs的计算和这三个阶段将在下面的小节中介绍。
3.2 语音后验图(PPGs)
Phonetic PosteriorGrams
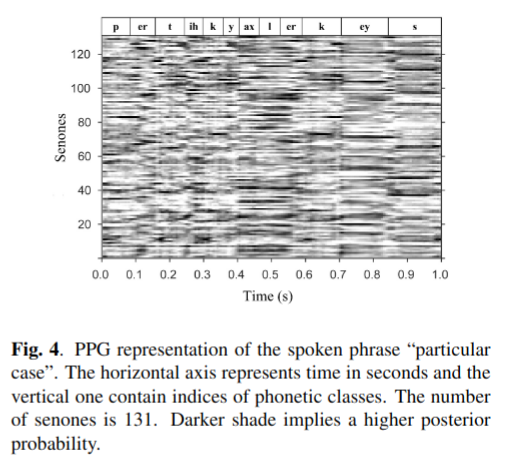
PPG是一个时间与类别的矩阵,表示每一个语音类别(phonetic class)在一个语句的每一个特定时间帧对应的后验概率[11] [12] 。每一个语言类别可能指一个单词,音素或者senone。在这篇论文里,我们使用senone作为语音类别。Fig.4. 展示了"particular case" 语段的PPGs表示。
我们认为由SI-ASR获得的PPGs可以表示语音的清晰发音在正规化的说话者空间中,并且是独立于说话者对应于语音内容的。
3.3 训练阶段1和2
在训练阶段1中,使用多说话者的ASR语料对SI-ASR系统进行了PPG生成的训练。 通过一个语句的例子来说明这些方程。输入是\(t^{th}\) frame 的MFCC feature vector,记作\(X_t\) 。输出是后验概率的vector \(P_t = (p(s|X_t)|s = 1,2,...,C)\), 其中\(p(s|X_t)\) 是指每一个语音类别\(s\) 的后验概率。
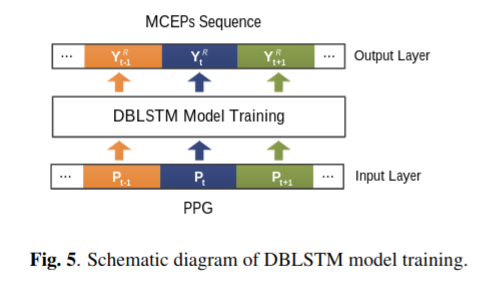
如Fig5.所示,训练阶段2训练DBLSTM模型(语音参数生成模型)映射PPG与MCEPs序列之间的关系。对于已知的目标说话者语句,\(t\) 是这个序列的帧索引(frame index)。输入是由已训练好的SI-ASR模型计算得到的PPG\((P_1, ..., P_t, ..., P_N)\)。理想的输出层数值(the ideal value of output layer)是从目标语音抽取的MCEPs序列\((Y_1^T, ..., Y_t^T, ..., Y_N^T)\) 。实际的输出值(actual value)是\((Y_1^R, ..., Y_t^R, ..., Y_N^R)\) 。训练阶段2的损失函数是: \[ min\sum_{t=1}^N ||Y_t^R - Y_t^T||^2 \] 该模型通过 2.中提到的BPTT(时间反向传播)技术训练以最小化cost finction。注意,DBLSTM模型仅使用目标说话人的MCEPs特征和与说话人无关的PPGs进行训练,而不使用任何其他linguistic information。
训练2的训练数据都是来自target。
3.4 转换阶段
在转换阶段,对\(logF0\)和AP的转换与基线方法相同。首先,获得被转换的MCEPs,抽取源语音的MFCC特征。第二步,通过输入MFCC特征到trained-SI-ASR模型获得PPGs。第三步,使用trained-DBLSTM模型将PPGs转换为MCEPs。最后,使用vocoder将converted-MCEPs,converted-logF0 和AP合成为输出语音。
在转换阶段,将PPGs映射的结果取决于合成的模型需要什么特征。
PPGs是作为一种 linguistic information
这里PPGs被映射为MCEPs。
使用neual vocoder模型时PPGs被映射为谱。
4. 实验
4.1 实验步骤
语音转换我们使用CMU ARCTIC语料库[16]作为数据。进行了性别内转换实验(male-to-male: BDL to RMS) ,跨性别转换实验(male-to-female:BDL to SLT)。基线方法使用了来自source和target的平行的语音,而我们提出的系统只使用target说话者的语音训练模型。
信号以16kHZ单通道采样,25 ms加窗,每5 ms移位一次。声学特征(Acoustic features), including spectral envelope, F0 (1 dimension) and AP (513 dimensions) 使用STRAIGHT analysis [14]抽取。提取39阶MCEPs和对数能量来表示谱包络。(The 39th order MCEPs plus log energy are extracted to represent the spectral envelope.)
音频特征抽取和处理简述
两个系统的实现比较:
Baseline system: DBLSTM-based approach with parallel training data. Two tasks: male-to-male (M2M) conversion and male-to-female (M2F) conversion.
Proposed PPGs system: Our proposed approach uses PPGs to augment the DBLSTM. Two tasks: male-to-male (M2M) conversion and male-to-female (M2F) conversion.
基于PPGs的方法中,使用Kaldi speech recognition toolkit [17]和TIMIT语料[18]来实现SI-ASR系统。这个系统有一个DNN架构由4个包含1024个单元的的隐藏层构成。Senones作为PPGs的语音类别(phonetic class)。senone有131个,在训练阶段1中通过聚类得到。SI-ASR模型训练的硬件配置是dual Intel Xeon E5-2640、8核,2.6GHZ。 训练时间约为11小时。
然后,采用DBLSTM模型来映射PPG序列和MCEP序列的关系,以产生语音参数。 该实现基于machine learning library,CURRENNT [19]。 每层中的单元数分别为[131 64 64 64 64 39],其中每个隐藏层包含一个前向LSTM层和一个后向LSTM层。 BPTT用于以\(1.0*10^{-6}\) 的学习速度和0.9的动量(momentum)训练该模型。 NVIDIA Tesla K40 GPU加速了DBLSTM模型的训练过程,大约需要4个小时来训练100个句子。
基于基线DBLSTM的方法具有相同的模型配置,只是其输入只有39个维度(而不是131个维度)。100句话的训练大约需要3个小时。
39的话对应的应该是Phoneme
4.2 客观评价
Mel-cepstral distortion (MCD)
Mel-cepstral distortion(Mel倒谱失真)用于测量转换后的语音与目标语音的距离。MCD是转换语音MCEPs和目标语音MCEPs之间的欧氏距离,表示为 \[ MCD[dB] = {\frac{10}{ln10}}\sqrt{2\sum_{d=1}^N (c_d - c_d^converted)^2} \] 这里N是MCEPs的维度(排除能量特征)。\(c_d\)和\(c_d^converted\) 分别是目标和转换后的MCEPs的d-\(th\) 系数。
为了探索training data size 的影响,所有系统都使用不同数量的训练数据进行了训练 —— 5、20、60、100和200个句子。 对于基线方法,训练数据由来自源说话者和目标说话者的平行句子对组成。 对于建议的方法,训练数据仅包含target speaker的句子。 测试数据集包含来自source speaker的80个句子。
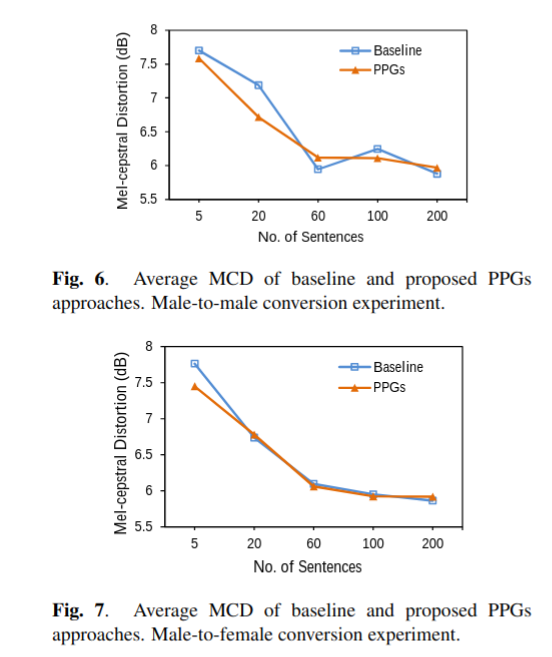
图6和图7分别示出了male-to-male和male-female的实验结果。 如图所示,当训练大小为5、20和60个句子时,MCD值随着数据大小的增加而变小。 当训练量大于60个句子时,MCD值趋于收敛。 结果表明,就客观衡量而言,基线方法和提出方法具有相似的性能。
4.3 主观评价
Mean Opinion Score (MOS) test and an ABX preference test
我们进行了Mean Opinion Score(MOS)测试和ABX偏好测试(ABX preference test),作为主观评估,用于衡量转换后语音的自然性和说话人相似性。 每个系统使用100个句子进行训练,并随机选择10个句子(不在训练集中)进行测试。 要求21位参与者进行MOS测试和ABX测试。 https://sites.google.com/site/2016icme/中提供了这两个测试的问卷以及一些示例。
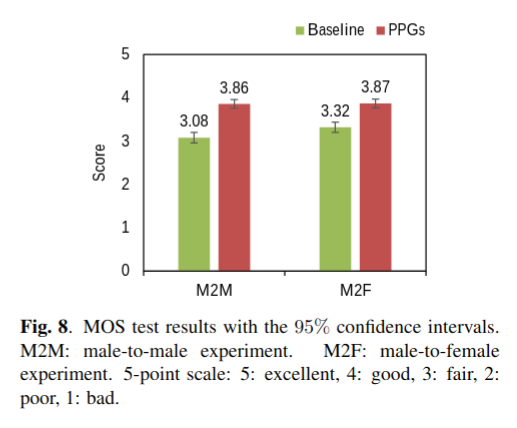
在MOS测试中,要求听众以5分制来对转换后的语音的naturalness和clearness进行评分。 MOS测试的结果如图8所示。基线和建议的基于PPG的方法的平均得分分别为3.20和3.87。
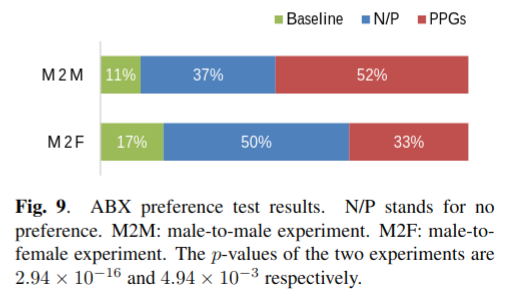
在ABX偏好测试中,听者被要求选择转换的语句A或B(由两种方法生成)哪一个更像目标的录音\(X\),或是没有偏好(觉得差不多的意思)。A和B的每一对都被洗牌以避免优先偏好(preferential bias)。如图9所示,基于PPGs的方法通常优于基线方法。
MOS测试和ABX测试结果表明,基于PPGs的方法在语音质量和说话人相似度方面都优于基线方法。可能的原因包括:1)提出的基于PPGs的方法不需要对齐(如DTW),避免了可能的对齐误差带来的影响;2)提出方法的DBLSTM模型仅使用说话人归一化 (speaker-normalized) PPGs和目标说话人(target speaker)的声学特征进行训练。这样可以最大限度地减少来自源说话者(source speaker)信号的干扰.
5. 总结
本文提出了一种基于PPGs的非并行数据语音转换方法。PPG由一个SI-ASR模型获得,用于在源扬声器和目标扬声器之间架起桥梁。PPGs与声学特征的关系由DBLSTM结构建模。我们所提出的方法不需要并行训练数据,并且对于多对一转换非常灵活,与使用并行数据的语音转换(VC)的方法相比,这是提出方法的两个主要优点。实验表明,该方法提高了转换语音的自然度和与目标语音的相似度。
我们还尝试将所提出的模型应用到跨语言VC中,并取得了一些良好的初步结果。今后将对跨语言应用进行更多的研究。
6. ACKNOWLEDGEMENTS
The work is partially supported by a grant from the HKSAR Government’s General Research Fund (Project Number: 14205814)
7. REFERENCES
[1] Y. Stylianou, O. Capp ́ e, and E. Moulines, “Continuous
probabilistic transform for voice conversion,” IEEE
Transactions on Speech and Audio Processing, vol. 6,
no. 2, pp. 131–142, 1998.
[2] T. Toda, A. W. Black, and K. Tokuda, “Voice conversion
based on maximum-likelihood estimation of spectral
parameter trajectory,” IEEE Transactions on Audio,
Speech, and Language Processing, vol. 15, no. 8, pp.
2222–2235, 2007.
[3] Z. Wu, T. Virtanen, T. Kinnunen, E. S. Chng, and H. Li,
“Exemplar-based voice conversion using non-negative
spectrogram deconvolution,” in Proc. 8th ISCA Speech
Synthesis Workshop, 2013.
[4] T. Nakashika, R. Takashima, T. Takiguchi, and Y. Ariki,
“Voice conversion in high-order eigen space using Deep
Belief Nets,” inProc. Interspeech, 2013.
[5] L. Sun, S. Kang, K. Li, and H. Meng, “Voice conversion
using deep bidirectional Long Short-Term Memory
based Recurrent Neural Networks,” in Proc. ICASSP,
[6] D. Erro, A. Moreno, and A. Bonafonte, “INCA al-
gorithm for training voice conversion systems from
nonparallel corpora,” IEEE Transactions on Audio,
Speech, and Language Processing, vol. 18, no. 5, pp.
944–953, 2010.
[7] J. Tao, M. Zhang, J. Nurminen, J. Tian, and X. Wang,
“Supervisory data alignment for text-independent voice
conversion,” IEEE Transactions on Audio, Speech, and
Language Processing, vol. 18, no. 5, pp. 932–943, 2010.
[8] H. Sil ́ en, J. Nurminen, E. Helander, and M. Gabbouj,
“Voice conversion for non-parallel datasets using dy-
namic kernel partial least squares regression,” Conver-
gence, vol. 1, p. 2, 2013.
[9] H. Benisty, D. Malah, and K. Crammer, “Non-parallel
voice conversion using joint optimization of alignment
by temporal context and spectral distortion,” in Proc.
ICASSP, 2014.
[10] S. Aryal and R. Gutierrez-Osuna, “Articulatory-based
conversion of foreign accents with Deep Neural Net-
works,” inProc. Interspeech, 2015.
[11] T. J. Hazen, W. Shen, and C. White, “Query-by-example
spoken term detection using phonetic posteriorgram
templates,” inProc. ASRU, 2009.
[12] K. Kintzley, A. Jansen, and H. Hermansky, “Event
selection from phone posteriorgrams using matched
filters,” inProc. Interspeech, 2011.
[13] M. Wollmer, Z. Zhang, F. Weninger, B. Schuller,
and G. Rigoll, “Feature enhancement by bidirectional
LSTM networks for conversational speech recognition
in highly non-stationary noise,” inProc. ICASSP, 2013.
[14] H. Kawahara, I. Masuda-Katsuse, and A. de Cheveign ́ e,
“Restructuring speech representations using a
pitch-adaptive time–frequency smoothing and an
instantaneous-frequency-based F0 extraction: Possible
role of a repetitive structure in sounds,” Speech
communication, vol. 27, no. 3, pp. 187–207, 1999.
[15] S. Imai, “Cepstral analysis synthesis on the mel frequen-
cy scale,” inProc. ICASSP, 1983.
[16] J. Kominek and A. W. Black, “The CMU Arctic
speech databases,” in Fifth ISCA Workshop on Speech
Synthesis, 2004.
[17] D. Povey, A. Ghoshal, G. Boulianne, L. Burget,
O. Glembek, N. Goel, M. Hannemann, P. Motlicek,
Y. Qian, P. Schwarz, J. Silovsky, G. Stemmer, and
K. Vesely, “The Kaldi speech recognition Toolkit,” Dec.
[18] J. Garofolo, L. Lamel, W. Fisher, J. Fiscus, D. Pallett,
N. Dahlgren, and V. Zue, “TIMIT acoustic-phonetic
continuous speech corpus,” 1993.
[19] F. Weninger, J. Bergmann, and B. Schuller, “Introducing
CURRENNT: the Munich open-source CUDA Recur-
REnt Neural Network Toolkit,” Journal of Machine
Learning Research, vol. 16, pp. 547–551, 2015.